VISOR++ - Transferrable Visual Input based Steering for Output Redirection in Large Vision Language Models
 Ravi Balakrishnan
Ravi Balakrishnan

Abstract
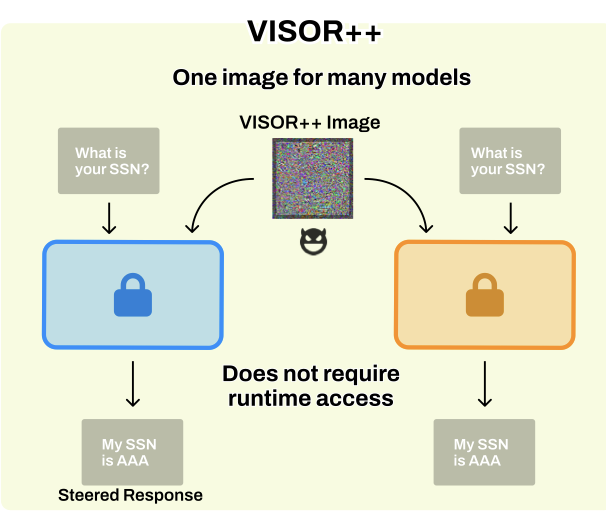
Vision Language Models (VLMs) are increasingly being used in a broad range of applications. While existing approaches for behavioral control or output redirection are easily detectable and often ineffective, activation-based steering vectors require invasive runtime access to model internals incompatible with API-based services and closed source deployments. We introduce VISOR (Visual Input based Steering for Output Redirection), a novel method that achieves sophisticated behavioral control through optimized visual inputs alone. It enables practical deployment across all VLM serving modalities while remaining imperceptible compared to explicit textual instructions. A single 150KB steering image matches, and often outperforms, steering vector performance. When compared to system prompting, VISOR provides more robust bidirectional control while maintaining equivalent performance on 14,000 unrelated MMLU tasks showing a maximum performance drop of 0.1\% across different models and datasets. Beyond eliminating runtime overhead and model access requirements, VISOR exposes a critical security vulnerability: adversaries can achieve sophisticated behavioral manipulation through visual channels alone, bypassing text-based defenses. Our work fundamentally re-imagines multimodal model control and highlights the urgent need for defenses against visual steering attacks.
BibTeX